Building OTP Applications
Why Would I Want That?

After seeing our whole application's supervision tree start at once with a simple function call, we might wonder why we would want to make things more complicated than they already are. The concepts behind supervision trees are a bit complex and I could see myself just starting all of these trees and subtrees manually with a script when the system is first set up. Then after that, I would be free to go outside and try to find clouds that look like animals for the rest of the afternoon.
This is entirely true, yes. This is an acceptable way to do things (especially the part about clouds, because these days everything is about cloud computing). However, as for most abstractions made by programmers and engineers, OTP applications are the result of many ad-hoc systems being generalised and made clean. If you were to make an array of scripts and commands to start your supervision trees as described above, and that other developers you work with had their own, you'd quickly run into massive issues. Then someone would ask something like "Wouldn't it be nice if everyone used the same kind of system to start everything? And wouldn't it even be nicer if they all had the same kind of application structure?"
OTP applications attempt to solve this exact type of problem. They give a directory structure, a way to handle configurations, a way to handle dependencies, create environment variables and configuration, ways to start and stop applications, and a lot of safe control in detecting conflicts and handling live upgrades them without shutting your applications down.
So unless you don't want these aspects (nor the niceties they give, like consistent structures and tools developed for it), this chapter should be of some interest to you.
My Other Car is a Pool
We're going to reuse the ppool application we wrote for last chapter and turn it into a real OTP application.
The first step in doing so is to copy all the ppool related files into a neat directory structure:
ebin/ include/ priv/ src/ - ppool.erl - ppool_sup.erl - ppool_supersup.erl - ppool_worker_sup.erl - ppool_serv.erl - ppool_nagger.erl test/ - ppool_tests.erl
Most directories will for now remain empty. As explained in the Designing a Concurrent Application chapter, the ebin/ directory will hold compiled files, the include/ directory will contain Erlang header (.hrl) files, priv/ will hold executables, other programs, and various specific files needed for the application to work and src/ will hold the Erlang source files you will need.
You'll note that I added a test/ directory just for the test file I had before. The reason for this is that tests are somewhat common, but you don't necessarily want them distributed as part of your application — you just need them when developing your code and justifying yourself to your manager ("tests pass, I don't understand why the app killed people"). Other directories like that end up being added as required, depending on the case. One example is the doc/ directory, added whenever you have EDoc documentation to add to your application.
The four basic directories to have are ebin/, include/, priv/ and src/ and they'll be common to pretty much every OTP application you get, although only ebin/ and priv/ are going to be exported when real OTP systems are deployed.
The Application Resource File
Where do we go from here? Well the first thing to do is to add an application file. This file will tell the Erlang VM what the application is, where it begins and where it ends. This file lives on in the ebin/ directory, along with all the compiled modules.
This file is usually named <yourapp>.app (in our case ppool.app) and contains a bunch of Erlang terms defining the application in terms the VM can understand (the VM is pretty bad at guessing stuff!)
Note: some people prefer to keep this file outside of ebin/ and instead have a file named <myapp>.app.src as part of src/. Whatever build system they use then copies this file over to ebin/ or even generates one in order to keep everything clean.
The basic structure of the application file is simply:
{application, ApplicationName, Properties}.
Where ApplicationName is an atom and Properties is a list of {Key, Value} tuples describing the application. They're used by OTP to figure out what your application does and whatnot, they're all optional, but might always be useful to carry around and necessary for some tools. In fact, we'll only look at a subset of them for now and introduce the others as we need them:
{description, "Some description of your application"}
This gives the system a short description of what the application is. The field is optional and defaults to an empty string. I would suggest always defining a description, if only because it makes things easier to read.
{vsn, "1.2.3"}
Tells what's the version of your application. The string takes any format you want. It's usually a good idea to stick to a scheme of the form <major>.<minor>.<patch> or something like that. When we get to tools to help with upgrades and downgrades, the string is used to identify your application's version.
{modules, ModuleList}
Contains a list of all the modules that your application introduces to the system. A module always belongs to at most one application and can not be present in two applications' app files at once. This list lets the system and tools look at dependencies of your application, making sure everything is where it needs to be and that you have no conflicts with other applications already loaded in the system. If you're using a standard OTP structure and are using a build tool like rebar3, this is handled for you.
{registered, AtomList}
Contains a list of all the names registered by the application. This lets OTP know when there will be name clashes when you try to bundle a bunch of applications together, but is entirely based on trusting the developers to give good data. We all know this isn't always the case, so blind faith shouldn't be used in this case.
{env, [{Key, Val}]}
This is a list of key/values that can be used as a configuration for your application. They can be obtained at run time by calling application:get_env(Key) or application:get_env(AppName, Key). The first one will try to find the value in the application file of whatever application you are in at the moment of the call, the second allows you to specify an application in particular. This stuff can be overwritten as required (either at boot time or by using application:set_env/3-4.
All in all this is a pretty useful place to store configuration data rather than having a bunch of config files to read in whatever format, without really knowing where to store them and whatnot. People often tend to roll their own system over it anyway, given not everyone is a fan of using Erlang syntax in configuration files.
{maxT, Milliseconds}
This is the maximum time that the application can run, after which it will be shut down. This is a rather rarely used item and Milliseconds defaults to infinity, so you often don't need to bother with this one at all.
{applications, AtomList}
A list of applications on which yours depends. The application system of Erlang will make sure they were loaded and/or started before allowing yours to do so. All applications depend at least on kernel and stdlib, but if your application were to depend on ppool being started, then you should add ppool to the list.
Note: yes, the standard library and the VM's kernel are applications themselves, which means that Erlang is a language used to build OTP, but whose runtime environment depends on OTP to work. It's circular. This gives you some idea of why the language is officially named 'Erlang/OTP'.
{mod, {CallbackMod, Args}}
Defines a callback module for the application, using the application behaviour (which we will see in the next section). This tells OTP that when starting your application, it should call CallbackMod:start(normal, Args). This function's return value will be used when OTP will call CallbackMod:stop(StartReturn) when stopping your application. People will tend to name CallbackMod after their application.
And this covers most of what we might need for now (and for most applications you'll ever write).
Converting the Pool
How about we put this into practice? We'll turn the ppool set of processes from last chapter into a basic OTP application. The first step for this is to redistribute everything under the right directory structure. Just create five directories and distribute the files as follows:
ebin/ include/ priv/ src/ - ppool.erl - ppool_serv.erl - ppool_sup.erl - ppool_supersup.erl - ppool_worker_sup.erl test/ - ppool_tests.erl - ppool_nagger.erl
You'll notice I moved the ppool_nagger to the test directory. This is for a good reason — it was not much more than a demo case and would have nothing to do with our application, but is still necessary for the tests. We can actually try it later on once the app has all been packaged so we can make sure everything still works, but for the moment it's kind of useless.
We'll add an Emakefile (appropriately named Emakefile, placed in the app's base directory) to help us compile and run things later on:
{"src/*", [debug_info, {i,"include/"}, {outdir, "ebin/"}]}.
{"test/*", [debug_info, {i,"include/"}, {outdir, "ebin/"}]}.
This just tells the compiler to include debug_info for all files in src/ and test/, tells it to go look in the include/ directory (if it's ever needed) and then shove the files up its ebin/ directory.
Speaking of which, let's add the app file in the ebin/ directory:
{application, ppool,
[{vsn, "1.0.0"},
{modules, [ppool, ppool_serv, ppool_sup, ppool_supersup, ppool_worker_sup]},
{registered, [ppool]},
{mod, {ppool, []}}
]}.
This one only contains fields we find necessary; env, maxT and applications are not used. We now need to change how the callback module (ppool) works. How do we do that exactly?
First, let's see the application behaviour.
Note: even though all applications depend on the kernel and the stdlib applications, I haven't included them. ppool will still work because starting the Erlang VM starts these applications automatically. You might feel like adding them for the sake of expliciteness, but there's no need for it right now.

The Application Behaviour
As for most OTP abstractions we've seen, what we want is a pre-built implementation. Erlang programmers are not happy with design patterns as a convention, they want a solid abstraction for them. This gives us a behaviour for applications. Remember that behaviours are always about splitting generic code away from specific code. They denote the idea that your specific code gives up its own execution flow and inserts itself as a bunch of callbacks to be used by the generic code. In simpler words, behaviours handle the boring parts while you connect the dots. In the case of applications, this generic part is quite complex and not nearly as simple as other behaviours.
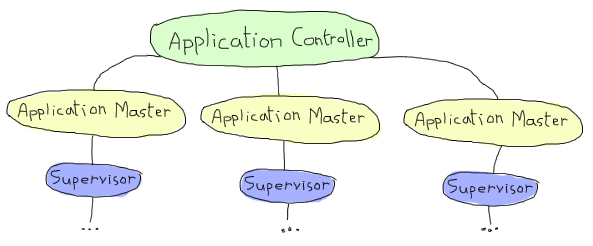
Whenever the VM first starts up, a process called the application controller is started (with the name application_controller). It starts all other applications and sits on top of most of them. In fact, you could say the application controller acts a bit like a supervisor for all applications. We'll see what kind of supervision strategies there are in the From Chaos to Application section.
Note: the Application Controller technically doesn't sit over all the applications. One exception is the kernel application, which itself starts a process named user. The user process in fact acts as a group leader to the application controller and the kernel application thus needs some special treatment. We don't have to care about this, but I felt like it should be included for the sake of precision.
In Erlang, the IO system depends on a concept called a group leader. The group leader represents standard input and output and is inherited by all processes. There is a hidden IO protocol that the group leader and any process calling IO functions communicate with. The group leader then takes the responsibility of forwarding these messages to whatever input/output channels there are, weaving some magic that doesn't concern us within the confines of this text.
Anyway, when someone decides they want to start an application, the application controller (often noted AC in OTP parlance) starts an application master. The application master is in fact two processes taking charge of each individual application: they set it up and act like a middleman in between your application's top supervisor and the application controller. OTP is a bureaucracy, and we have many layers of middle-management! I won't get into the details of what happens in there as most Erlang developers will never actually need to care about that and very little documentation exists (the code is the documentation). Just know that the application master acts a bit like the app's nanny (well, a pretty insane nanny). It looks over its children and grandchildren, and when things go awry, it goes berserk and terminates its whole family tree. Brutally killing children is a common topic among Erlangers.
An Erlang VM with a bunch of applications might look a bit like this:
Up to now, we were still looking at the generic part of the behaviour, but what about the specific stuff? After all, this is all we actually have to program. Well the application callback module requires very few functions to be functional: start/2 and stop/1.
The first one takes the form YourMod:start(Type, Args). For now, the Type will always be normal (the other possibilities accepted have to do with distributed applications, which we'll see at a later point). Args is what is coming from your app file. The function initialises everything for your app and only needs to return the Pid of the application's top-level supervisor in one of the two following forms: {ok, Pid} or {ok, Pid, SomeState}. If you don't return SomeState, it simply defaults to [].
The stop/1 function takes the state returned by start/2 as an argument. It runs after the application is done running and only does the necessary cleanup.
That's it. A huge generic part, a tiny specific one. Be thankful for that, because you wouldn't want to write the rest of things too often (just look at the source if you feel like it!) There are a few more functions that you can optionally use to have more control over the application, but we don't need them for now. This means we can move forward with our ppool application!
From Chaos to Application
We have the app file and a general idea of how applications work. Two simple callbacks. Opening ppool.erl, we change the following lines:
-export([start_link/0, stop/0, start_pool/3,
run/2, sync_queue/2, async_queue/2, stop_pool/1]).
start_link() ->
ppool_supersup:start_link().
stop() ->
ppool_supersup:stop().
To the following ones instead:
-behaviour(application).
-export([start/2, stop/1, start_pool/3,
run/2, sync_queue/2, async_queue/2, stop_pool/1]).
start(normal, _Args) ->
ppool_supersup:start_link().
stop(_State) ->
ok.
We can then make sure the tests are still valid. Pick the old ppool_tests.erl file (I wrote it for the previous chapter and am bringing it back here) and replace the single call to ppool:start_link/0 to application:start(ppool) as follows:
find_unique_name() ->
application:start(ppool),
Name = list_to_atom(lists:flatten(io_lib:format("~p",[now()]))),
?assertEqual(undefined, whereis(Name)),
Name.
You should also take the time to remove stop/0 from ppool_supersup (and remove the export), because the OTP application tools will take care of that for us.
We can finally recompile the code and run all the tests to make sure everything still works (we'll see how that eunit thing works later on, don't worry):
$ erl -make Recompile: src/ppool_worker_sup Recompile: src/ppool_supersup ... $ erl -pa ebin/ ... 1> make:all([load]). Recompile: src/ppool_worker_sup Recompile: src/ppool_supersup Recompile: src/ppool_sup Recompile: src/ppool_serv Recompile: src/ppool Recompile: test/ppool_tests Recompile: test/ppool_nagger up_to_date 2> eunit:test(ppool_tests). All 14 tests passed. ok
The tests take a while to run due to timer:sleep(X) being used to synchronise everything in a few places, but it should tell you everything works, as shown above. Good news, our app is healthy.
We can now study the wonders of OTP applications by using our new awesome callbacks:
3> application:start(ppool).
ok
4> ppool:start_pool(nag, 2, {ppool_nagger, start_link, []}).
{ok,<0.142.0>}
5> ppool:run(nag, [make_ref(), 500, 10, self()]).
{ok,<0.146.0>}
6> ppool:run(nag, [make_ref(), 500, 10, self()]).
{ok,<0.148.0>}
7> ppool:run(nag, [make_ref(), 500, 10, self()]).
noalloc
9> flush().
Shell got {<0.146.0>,#Ref<0.0.0.625>}
Shell got {<0.148.0>,#Ref<0.0.0.632>}
...
received down msg
received down msg
The magic command here is application:start(ppool). This tells the application controller to launch our ppool application. It starts the ppool_supersup supervisor and from that point on, everything can be used as normal. We can see all the applications currently running by calling application:which_applications():
10> application:which_applications().
[{ppool,[],"1.0.0"},
{stdlib,"ERTS CXC 138 10","1.17.4"},
{kernel,"ERTS CXC 138 10","2.14.4"}]
What a surprise, ppool is running. As mentioned earlier, we can see that all applications depend on kernel and stdlib, which are both running. If we want to close the pool:
11> application:stop(ppool).
=INFO REPORT==== DD-MM-YYYY::23:14:50 ===
application: ppool
exited: stopped
type: temporary
ok
And it is done. You should notice that we now get a clean shutdown with a little informative report rather than the messy ** exception exit: killed from last chapter.
Note: You'll sometimes see people do something like MyApp:start(...) instead of application:start(MyApp). While this works for testing purposes, it's ruining a lot of the advantages of actually having an application: it's no longer part of the VM's supervision tree, can not access its environment variables, will not check dependencies before being started, etc. Try to stick to application:start/1 if possible.
Look at this! What's that thing about our app being temporary? We write Erlang and OTP stuff because it's supposed to run forever, not just for a while! How dare the VM say this? The secret is that we can give different arguments to application:start. Depending on the arguments, the VM will react differently to termination of one of its applications. In some cases, the VM will be a loving beast ready to die for its children. In other cases, it's rather a cold heartless and pragmatic machine willing to tolerate many of its children dying for the survival of its species.
- Application started with:
application:start(AppName, temporary) - Ends normally: Nothing special happens, the application has stopped.
- Ends abnormally: The error is reported, and the application terminates without restarting.
- Application started with:
application:start(AppName, transient) - Ends normally: Nothing special happens, the application has stopped.
- Ends abnormally: The error is reported, all the other applications are stopped and the VM shuts down.
- Application started with:
application:start(AppName, permanent) - Ends normally: All other applications are terminated and the VM shuts down.
- Ends abnormally: Same; all applications are terminated, the VM shuts down.
You can see something new in the supervision strategies when it comes to applications. No longer will the VM try to save you. At this point, something has had to go very, very wrong for it to go up the whole supervision tree of one of its vital applications, enough to crash it. When this does happen, the VM has lost all hope in your program. Given the definition of insanity is to do the same thing all over again while expecting different outcomes each time, the VM prefers to die sanely and just give up. Of course the real reason has to do with something being broken that needs to be fixed, but you catch my drift. Take note that all applications can be terminated by calling application:stop(AppName) without affecting others as if a crash had occurred.
Library Applications
What happens when we want to wrap flat modules in an application but we have no process to start and thus no need for an application callback module?
After pulling our hair and crying in rage for a few minutes, the only other thing left to do is to remove the tuple {mod, {Module, Args}} from the application file. That's it. This is called a library application. If you want an example of one, the Erlang stdlib (standard library) application is one of these.
If you have the source package of Erlang, you can go to otp_src_<release>/lib/stdlib/src/stdlib.app.src and see the following:
{application, stdlib,
[{description, "ERTS CXC 138 10"},
{vsn, "%VSN%"},
{modules, [array,
...
gen_event,
gen_fsm,
gen_server,
io,
...
lists,
...
zip]},
{registered,[timer_server,rsh_starter,take_over_monitor,pool_master,
dets]},
{applications, [kernel]},
{env, []}]}.
You can see it's a pretty standard application file, but without the callback module. A library application.
How about we go deeper with applications?